Polkadot for Reprap - Potential Worries
I've previously written about how Repraps are different. They let users make and spread copied machines without permission or royalties. I've written about how lots of people, including myself, did this.
Going against economics of scale and specialization, it was inefficient. A few companies caught up and outrun us in the past ~5 years. I marvel at how good the designs became, and how robust the community got, even before these star companies finally did capture the market.
Running like crazy in the innovation track of 3d printing was a lot of fun. Doing it with awesome strangers, without asking permission or paying royalties was a privilege.
I've though about ways to spur a new open period, concluding that more automation and rewards are required to re-distribute Reprap. I've suggested implementing network protocols for decentralized manufacturing, and pointed to the success blockchain projects have had in building decentralized permissionless databases.
I've been a blockchain dilettante for many years, lacking the real skill to innovate in the blockchain/protocol direction. So I went to Polkadot Academy to see if I could fix that. It was a four-week in-person course about cryptography, blockchain, Polkadot, Substrate, Frame, and implicitly about Parity and the parachains.
This is not an introductory text about Polkadot, so I'll just briefly define those words:
- Cryptography: Garbling data in ways that add or preserve value or meaning.
- Blockchain: Chunked sequence(s) of data where each new chunk contain garbled representation(s) of previous chunk(s).
- Polkadot: Most blockchains are used in contexts where old data must never be overwritten. Polkadot is a service preventing adversarial overwrites of blockchains.
- Substrate: A software development kit for building blockchains. Used for building Polkadot and its parachains.
- Frame: Helper code for building and using plug-ins within Substrate.
- Parity: The company who develops Substrate, Frame, Polkadot, and some of the parachains.
- Parachains: Blockchains who use Polkadot to safeguard their old blocks.
My Polkadot Background
Before going to the Academy, I had a fantastic impression of Polkadot, almost too good to be true. Suspecting that I might be overly positive, I Googled around for good criticism, but the articles I found were either dated or not relevant to my goals.
Now, after the Academy I want to try writing the post I was searching for.

"Reliability Is Our Goal, Decentralization Is Just a Tool"
Gavin Wood is the founder of Polkadot and CEO of Parity. He gave a welcome speech from the high table shown above.
The speech's main point was that decentralization is a tool, not an end goal. The real goal of Polkadot is reliability. Some decentralization improves reliability, and that's why Polkadot is somewhat decentralized. This is how I understood the speech.
I love reliability. But it's a slippery goal since it's only measurable in retrospect.
We don't have access to future hindsight. So we can't use it to guide current decentralization efforts.
Why dampen our decentralization expectations?
Maybe Parity is planning to let down nerds like myself, who find decentralization valuable on its own.
Gavin didn't dismiss decentralization entirely, he just downgraded it to a necessary evil. Which might be true for him. Still a red flag for me.
Even decentralization isn't perfect either. It is only interesting if it comes from permissionlessness and low thresholds. Emphasis on those terms would better match my goals.
As mentioned, Reprap temporarily suspended economic gravity through self-replication. More successful companies emerged from Reprap than the whole 3d printing industry had before Reprap. It was fun.
Polkadot's ability to hot-swap it's own WASM internals (self-upgrade in Reprap lingo), as well as the advanced on-chain governance, sounds like it's awfully close to the self-replication threshold that Reprap crossed. Successful software projects who crossed the threshold are gcc and Linux, who compile and copy new versions of themself, within themself.
I'm just dying to see Polkadot walk the last mile to enable cheap exponential growth through self-replication. They're halfway there. My worry is that they could start walking backwards in the name of pragmatism. Become a Makerbot, in Reprap lingo.

Lots of Power Concentrated in One Person
Before his speech, and at many other occasions during the Academy, Gavin was introduced as Doctor Gavin Wood.
He holds a degree but not in a related field. Phds are ubiquitous in hi-tech workplaces, which makes it a bad habit to repeatedly mention unrelated ones.
Doing so anyways is common in the UK, so it doesn't say much about Polkadot on its own, although other peoples' phds went unmentioned throughout the Academy.
I felt the title mentioning around Gavin was part of a broader tendency, that people changed behavior when Gavin was around.
The special treatment of Gavin is understandable. He is the locus of power in Parity: Founder, CEO, designer, public figurehead, and incredibly wealthy. He coded large critical parts of Polkadot on his own, including governance. The Academy I went to was his idea.
His ideas get implemented and he's not treated as expendable. He's on the one hand a servant of a higher goal, but he's also the one who formulates the goals.
If you want to trust Polkadot's future, you must first trust Gavin. Many at the Academy didn't have a problem with this trust, they even displayed the opposite problem of idolizing him. This is as understandable as it is problematic.
There's risk that ideas and concerns won't flow freely if the system designer is idolized and/or could fire you. I would prefer if the project's followers leaned more on core principles and less on a singular person.
Bowyer removed himself from formal power within Reprap. Satoshi did the same within Bitcoin. Gavin is different. The concentration of power over the project is a red flag to me.
Parity is Building a Star-Shaped Network
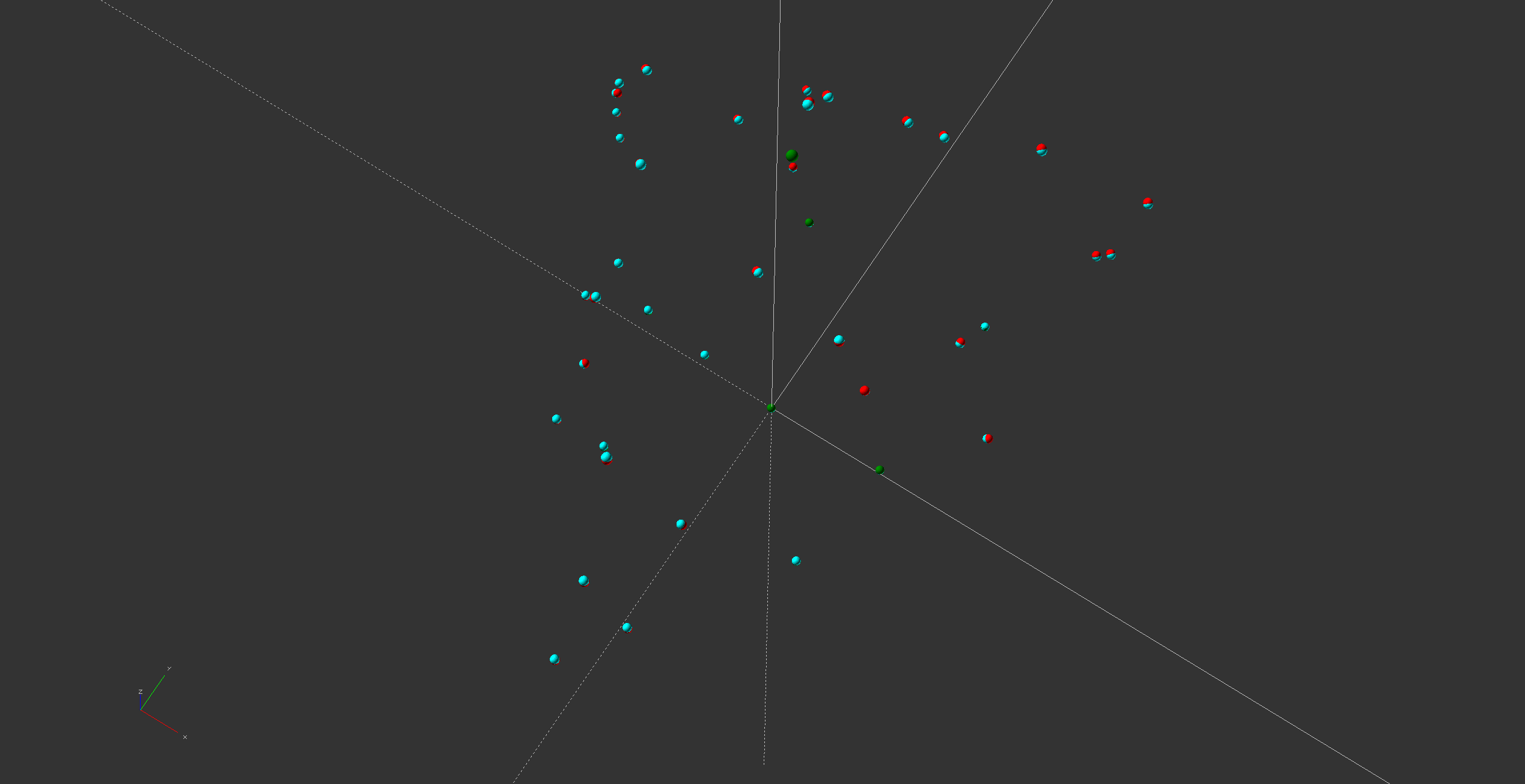
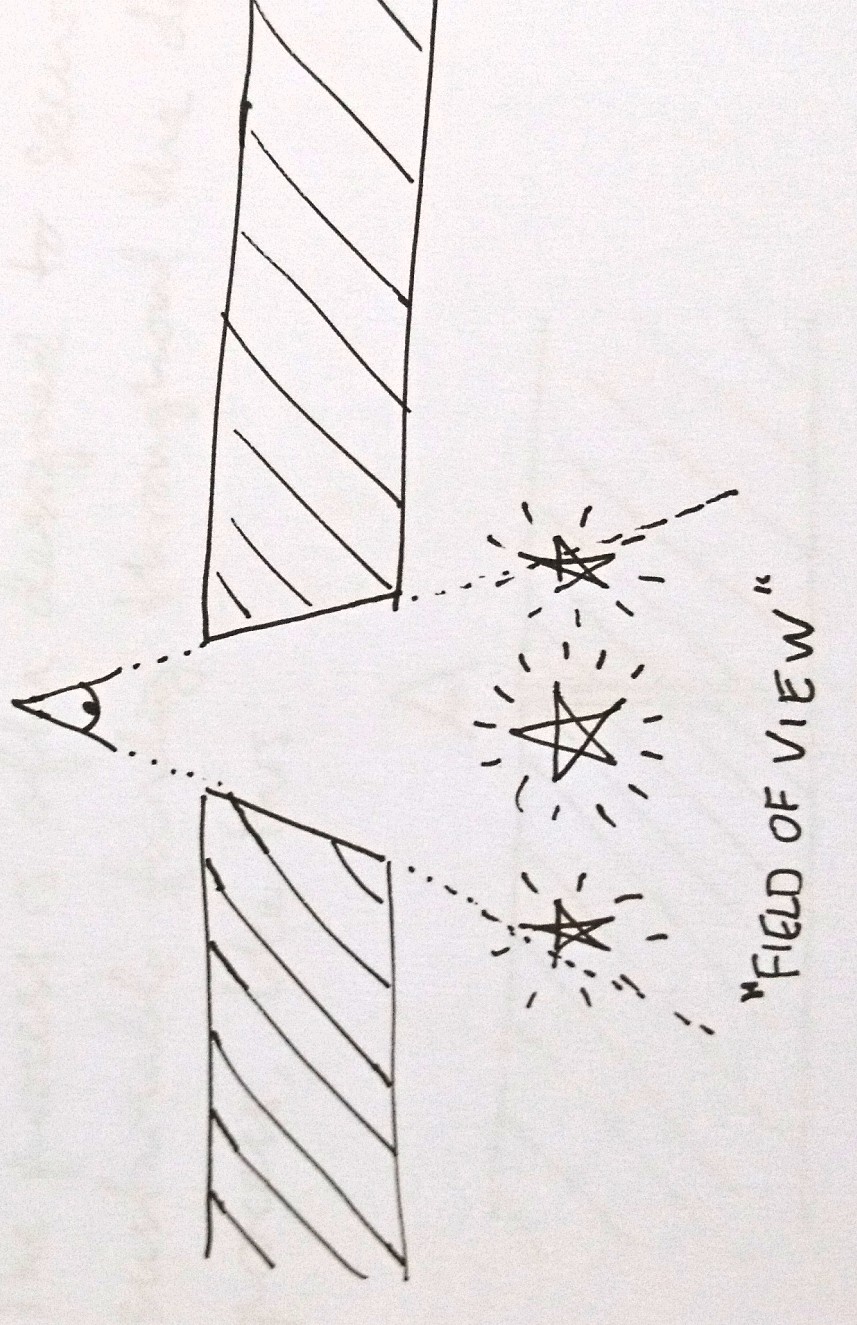
Polkadot's own documentation (link) shows the Polkadot network's topology like this:
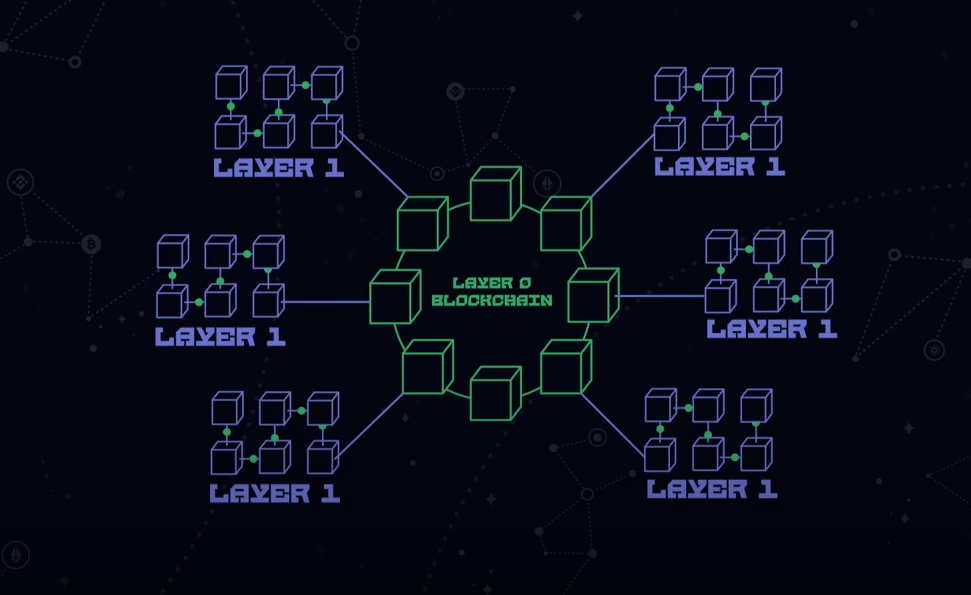
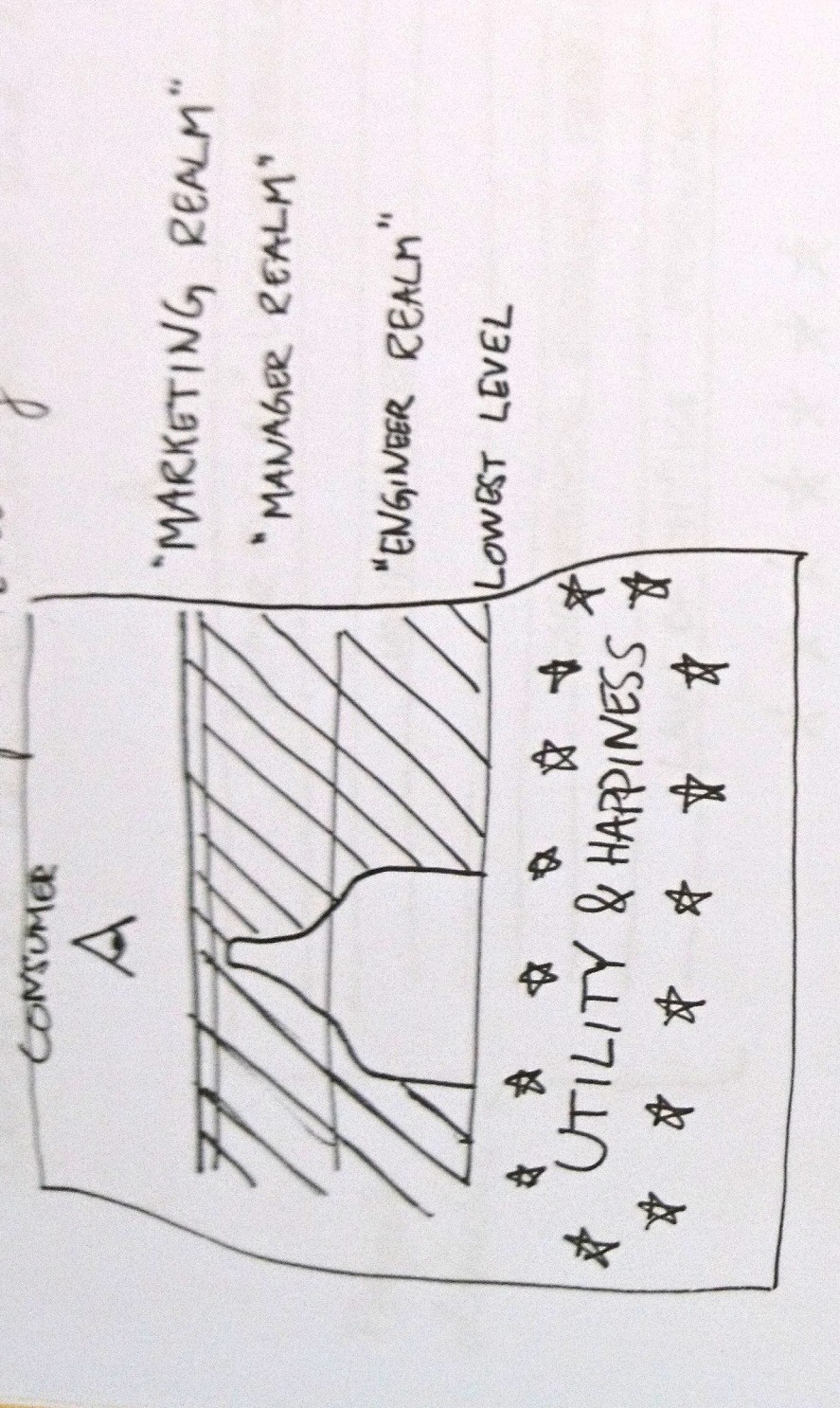
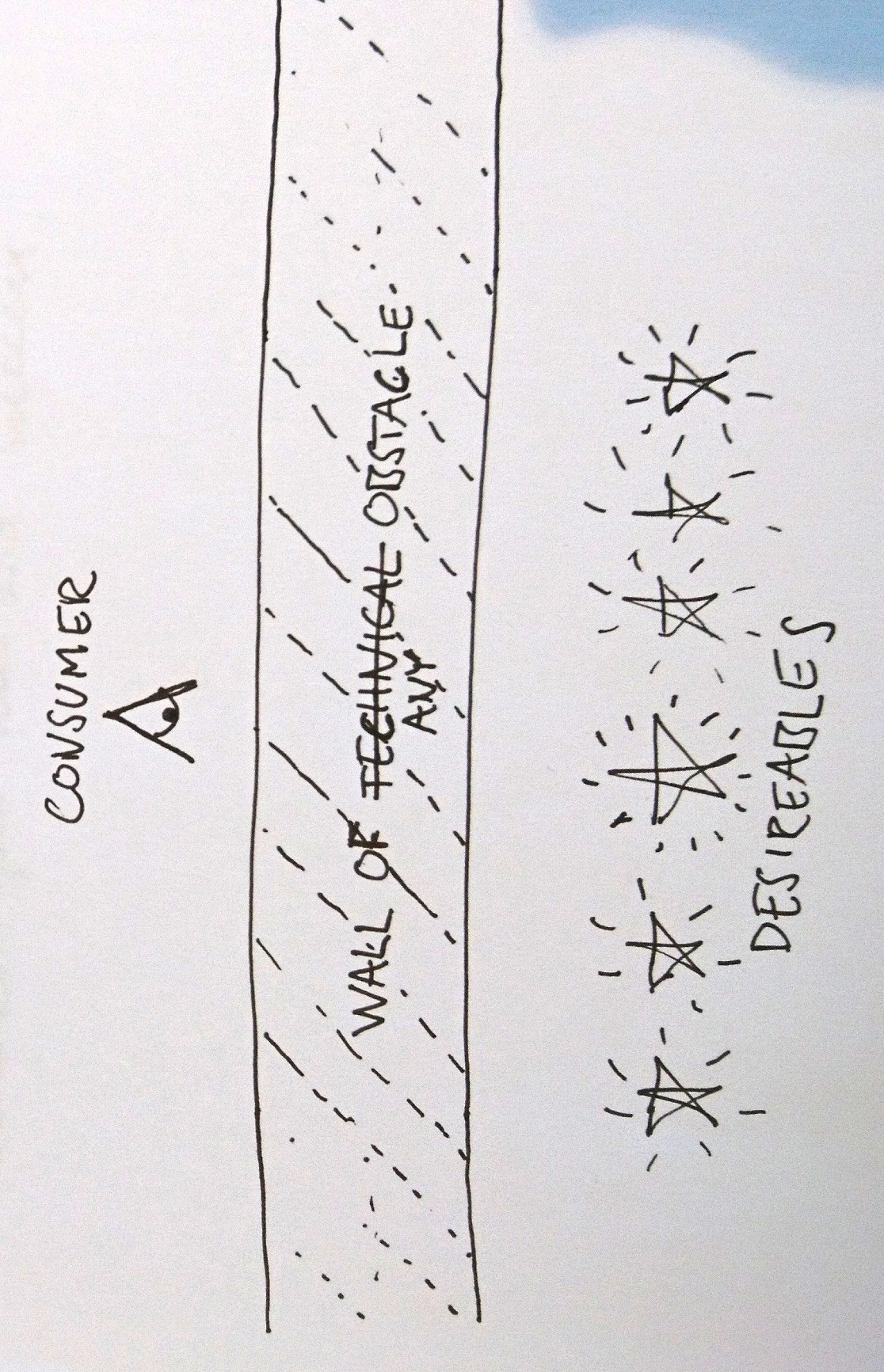
Network topology determine power relations in a network and differentiates fragile networks from reliable ones. The image shows a very special network topology called star shape. It is the most centralized and most fragile of all network topologies.
I have written about star shaped networks before, in a blog post called Hopes, Dreams, and Agendas. Here's the most relevant part from that post:
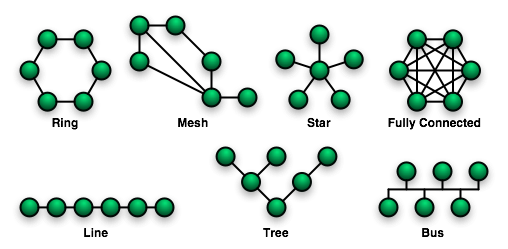
Polkadot's designers could have opted for any other topology but chose star shape, and they chose to put themselves at the center, contrary to eg Cosmos and to some degree Avalanche. There's a reason for the star of course. Those other blockchains don't deliver the shared security that Polkadot does.
Still, trading away all decentralization at the blockchain architecture level is a strong statement. Delivering shared security today is the most important goal to Polkadot's designers, more important than decentralizing the chains' network architecture.
This can be compared to the Internet, who replaced or swallowed its centralized predecessors. It was given a maximally distributed topology at first, in the name of robustness, and over time gravitated back towards clusters of more performant stars.
Polkadot's blockchain started out with star shape and gravity might pull it, as well as it's creators, hard into the center of their own star, locking them in place, for a few reasons:
The star shape is replicated in the social and economical systems within the network. All or almost all parachain devs is or has been economically dependent on grants paid by the Web3 Foundation (W3F), which is Parity's non-profit arm. Parity also arranges and control access to almost every social event in the network. If you want to meet Polkadot people, you go via Parity.
Polkadot must stay connected to all nodes and must find ways to collect taxes indefinitely. This is because it provides security to all the parachains from a single pooled source. Distributing the responsibility for such pooled security among parachains would lead to a tragedy of the commons. Every parachain would be incentivized to use the pooled security as much as possible while contributing as little as possible.
Taxes are currently collected through transaction fees, inflation, and parachain slot auctions. For fees, 80% are sent to the Polkadot treasury, which is controlled by Gavin Wood and 12 other people, 9 of whom are Parity/W3F employees, 2 represent specific parachains, and 1 is unknown to me. Some DOT inflation also goes straight to the treasury.
The slot auctions temporary lock up DOT tokens, increasing price and relative voting power of all other DOT holders. The Polkadot network itself is a sizeable DOT holder through its treasury.
Only Parity can maintain Substrate. Everyone else depend on Substrate. Parity has made Substrate into a large and very complex code repo. They keep it operational while chasing the cutting edge of cryptography research. To achieve both at the same time, they pay high salaries to hundreds of researchers and programmers. The cash flow and technical know-how required to maintain this quite experimental code base is very high. In fact impossible for any other company, and this will not change easily.

Parity has leverage to place arbitrary burdens on smaller parachains. Larger parachains have incentives to let them do that. The larger or majority of parachains will benefit from letting Parity push smaller competitors down.
Everything will be done in the name of improving the network as a whole. We see this already with the rollout of XCM and XCMP. Every parachain is expected to put a post-office-like virtual machine at the gate of their chain, where code from foreign blockchains are to be executed and acted upon.
I might be overly pessimistic here. The XCM and XCMP rollout still has time to play out and might still become a net positive for smaller chains. But changes will keep rolling out and the incentives for established players to tax newcomers will only grow over time.
Existing examples of maintenance taxes that limit smaller parachain teams are the frequent and unreliable release schedules from Parity, and the slow, expensive, recurring and unavoidable parachain slot auctions.

Reliability is Not for the Guest Chains
As mentioned before, parachains need protection against overwrites of their old blocks, and Polkadot is a service for providing such security.
However, Polkadot is a subscription service. Parachains subscribe to, or lease, their slot in the Polkadot network. A lease is very hard to obtain and lasts for a maximum of two years.
Leases are distributed through an intricate game called candle auctions. If parachains can't win a candle auction or obtain a lease on the second hand market, they loose their security and stop working.
This unreliability is designed right into the user-facing part of Polkadot's ecosystem. The power imbalance of it has made me think of Polkadot as the Daddy Chain, and parachains as Guest Chains.
If Parity wanted to deliver user-facing reliability then they would provide longer term leases or outright sell ownership of slots. Or they could build all parachains themselves.
Placing fundamental limitations on the security of the user-facing layer is a red flag for me.
Current parachains are planning to mitigate this threat by amassing funds enough to dominate future slot auctions. Some also plan to build out independent security mechanisms. They're very wise and plan ahead. I'd say most likely they'll make it.
But even if it plays out perfectly for them, the issue of looming insecurity still dampens my enthusiasm as a builder. Imagine in 2009, if Bitcoin could plausibly loose all mining power at discrete planned events in 2011, 2013, 2015, ... Or imagine if Ethereum's difficulty bomb was bound by a two year old contract, back in 2019. Or if Repraps were designed for planned obsolescence within two years.
Parathreads is a simpler service where blockchain projects can buy security on-demand, block-by-block, without any auction. It could help small blockchains gradually scale up.
Parathreads are less likely to save dislodged parachains from going down, since the chains would experience technical and reputational downgrade, both at once. Users can quickly evacuate dying guest chains through eg XCM.
Is Rust Reliable?
Parity use the Rust programming language exclusively for everything, including for all of Substrate.
Rust is good for reliability because it has a borrow-checker, pedantic default compiler flags, and a strong type system.
But Rust is also bad for reliability because it is immature. It is only 12 years old, which is young compared to eg C++, which is 37 years old. The Rust toolchain, best practices, and indeed the Rust programmers themselves have not had time to mature and accumulate long-term learnings. During these 12 years Rust has had only one real compiler, which has been changing frequently, and it quite frankly has bugs.

Anecdotally, I stumbled across a compiler bug during my first week of the Academy. Compiler bugs are highly unusual in other languages.
I had to use the nightly build of the Rust toolchain, otherwise I couldn't compile Substrate.
Polkadot inherits reliability and unreliability from Rust. Facing a bug at the compiler level, and being pushed over on nightly, was a red flag for me.
Can Static Analysis Make Up For Lack of Compiler Alternatives?
It could, I wish it did. The first thing I tried in the Substrate repo was:
$ rust-analyzer analysis-stats .
This is the most basic command to collect static analysis output, with the most common tool. It crashed.
The problem was fixed on Aug 1, so I gave it another try. It finished in 33 minutes and produced an analysis that wasn't right.
A singular compiler accompanied by a disappointing static analysis tool is a red flag for me.

The Way Parity Uses Rust Might Not Be the Most Reliable
As mentioned above, only the nightly version of the Rust toolchain would compile Substrate. Nightly is kind of the opposite of reliable and I saw it used across Parity (naturally, because they need to compile Substrate too). Seeing this made me wonder what reliability really means in the Polkadot context.
Similarly, Parity programmers are guaranteed to meet the same problems with rust-analyzer as I did. If they use rust-analyzer at all, which I think many don't. The frequent bugs and long time to finish means it's unpractical for large code bases.
But it's not just the tools and the language. I also worry about how Parity uses them. Rust is full of cool features and Parity has many new programmers. To borrow a phrase from a more experienced programmer: "History tells us that programmers feel compelled to try every feature of their new language during the first project, [...]" (link)
I think Parity might be over-using three language features:
- Proc macros
- Traits
- Comments
Substrate Relies Heavily on Esoteric and Over Powered Macros
A proc macro is almost a compiler in itself. It is made executable early in the compilation process. Later in the compilation process, it receives character streams from the compiler, and returns potentially very different characters back to the compiler, which then gets compiled as valid Rust code.
Proc macros were the language feature that made rust-analyzer crash on me. The internal proc macro interfaces are not stable, and rust-analyzer tripped. It's very hard for rust-analyzer to properly support proc macros for many reasons. (source)
It's similarly hard for programmers to use proc macros. They change the syntax of the language, generally away from beauty and towards brevity and often obfuscation. This creates steep learning curves and circuitous debugging sessions. Fixing a proc macro bug, and teaching a proc macro interface are both arduous tasks.
We know this because many Lisp projects made heavy use of similar mega powerful macros back in the 70s, 80s, and 90s. Domain experts created opaque mini-languages within Lisp, that died rather quickly because language design is hard. The over-use of macros contributed to Lisp loosing mindshare to simpler languages like C and Java.
The history of macros was unknown to the Parity programmers I met. This was a red flag for me.

Lots of Traits and Types, Little Logic
Traits are a language feature that lets you abstract over types easily. To specify logic in a Frame pallet, you plug type names into pre-defined traits. All types that could be abstracted over in Frame, are abstracted over, including integer types.
Most of the code talks about resolving abstracted types to concrete types, not about resolving variables or function calls into values.
The desirable outcome is that types and their behavior are very specific and extendable. You provide a type into an interface and the compiler tells you which functions are missing. Libraries can ship different plug-and-play types to choose from, and users can put them together like Legos.
The problem is that different types fulfilling lots of traits can be much harder than Legos to fit together.
For example in my own code, I was asked by the compiler to implement translations between the same type with two different names:
<<T as pallet::Config>::Currency as Currency<<T as frame_system::Config>::AccountId>>::Balance
and
<<T as pallet_referenda::Config>::Currency as Currency<<T as frame_system::Config>::AccountId>>::Balance
These two names resolve to the same concrete type, but the compiler can't detect that. I ended up using the one type who easily translates to the two different Balance-types: unsigned 32-bit integers. That is a less specific type than I would have used in a simpler language.
Most Academy student friends ended up side-stepping the complex type machinery like this in the interest of time. Maybe we just weren't enlightened enough, or maybe some type ceremonies were needlessly convoluted.
Either way, the time spent in the trait weeds was a red flag for me.
Substrate Makes Heavy Use of Comments
The comments inside the Substrate codebase are often 100 lines or more. There is an unusual amount of comments across the Substrate codebase.
Comments age badly because they require manual expert maintenance. They get outdated very quickly and lead new devs awry.
Parity programmers are conscientious and meticulous people, but they are also humans with deadlines, so comment maintenance will slip sometimes, even for them. Rust lets you put runnable tests within comments, but Substrate's comments consist mainly of natural language. I predict that Parity will have to delete most comments within a few years.
Their manually written online documentation have similar maintenance downsides. I tripped in outdated online tutorials many times during my time at the Academy.
The lesser evil alternative is to make the code itself human readable. Self-documenting code is a common ideal and best practice that limits the need for comments and hand written documentation.
I found Substrate's code hard to read, mainly because of macros usage, double-naming, and numerous verbose trait bounds. Large comments paired with low code readability was a red flag to me.

Practical End-to-end Testing Doesn't Exist in the Substrate Ecosystem
One method to try to predict reliability of a software system is to look at its testing regime. Coming from telecom, I expected to be presented with a tool that works like this:
- One set of files describe different toy test networks in terms of hardware and connections.
- Another kind of file lets devs specify external stimuli, sequential or in parallel, alongside expected network reactions, both within and flowing out of each node.
- A tool spins up or connects nodes according to the network specification, creates the specified stimuli and compares the network's reaction to the pre-defined expectations.
- The tool should also let the developer jump into the network to query nodes and read logs while still running.
I was told that no such tool exists. However there's something Zombienet that might grow up to address my concerns one day. I don't understand how developers build trust in their networks without enforcing such tests on every commit.
There should be warehouses full of machines simulating attacks for developers. Polkadot and parachain devs need this service. Lack of practical higher level testing options is a red flag to me.
Regression
I talked to parachain devs about how they handle the combination of frequent releases of Rust and Substrate with limited tools for testing and static analysis. The answer went something like this:
"We face bugs in other dependencies but also in Substrate itself. We search through old versions until we find combinations that work bug-free enough for our use case."
This pattern of having to search for compatible old versions is called regression; a return to a former or less developed state. It is what you get when the solution to an old bug creates a new bug, and the new bug gets shipped, breaking things that worked before. It's what makes my wife weary of updating her operating system, and what keeps banks running COBOL for decades.
As a systems programmer, fighting regression is the main boss. It's like facing a T-Rex and herding cats at the same time.

Clamping down on a regression spiral is hard. You must develop a new and more rigorous testing regime. You must probably drop some features and speak to each downstream programmer who used them, if you even know who they are.
Hopefully Substrate isn't that bad off. Maybe the devs I talked to were just using it wrongly. Anyways, what qualifies as regression should be defined by the user. Hearing how often they faced it was a red flag for me.
Last Words
Polkadot as a software solution to adversarial blockchain overwrites, is big and hairy. But solutions to specific problems in computer science are often quite hairy, especially if heavy usage is expected. Eg Fibonacci heaps come to mind. (link).
Software being hairy is not a deal breaker for my Reprap goals. Neither are my complaints about proc macros, traits, and comments.
Polkadot is young and will look very different in a few years. All computer programs are notoriously unfinished, that's the nature of programming. The only problem-free repo is an empty one. Projects don't show strength by not having problems, but by which type of problems they have, and over time how they solve them.
I will keep a look-out for the following:
- Is Gavin Wood detaching himself from the Project? A yes would inspire confidence.
- Is the star shaped topology broken up over time? Again, a yes would inspire confidence.
- Are guest chains offered something better than candle auctions and 2-year leases? Offerings should span any time range continuously and be straight-forward to get.
- Are we moving away from Rusts compiler being a single point of failure? The current emphasis on the generality of WASM and at the same time the superiority of Rust, and implicitly of the one Rust compiler, is somewhat contradictory.
- Do we see organic adoption of Frame? I've only seen paid devs wade through the macro-and-trait weeds so far. Seeing students fiddle with this voluntarily on their own time would inspire far more confidence.
- Is Substrate's broad generality utilized by anyone? If no, does Parity narrow its scope fast enough? Every multifaceted project must prove their flexibility by killing their darlings to prioritize project goals.
- Are Polkadot's parachains reliable? If yes, did a small team ship that? Small teams shipping stable services would inspire confidence. Large parachain projects facing downtime would inspire the opposite.
- Does regression in Substrate decrease over time? A publicly posted, low or decreasing measure of regression would inspire confidence. Such a measure could be constructed either through heavy testing or by counting how quickly and successfully users upgrade to the latest version.
This post focused on potential worries. To decide if Polkadot is a fit with my specific Reprap goals I must also consider the potential value of Polkadot's features.
That's a whole other text, but I should mention that valuable features exist that fit my Reprap goals. These are all features that might allow Polkadot to break out of its star shape in the future, like open source licenses and broad mind-share.
Compared to some of their competitors, Polkadot and Parity still look very good in my opinion. It's fun to see them run fast in the blockchain innovation track.
I own some DOT tokens and nothing I write is financial advice.
If you spot mistakes or have comments to this blog post, please reach out.
As my friend Ankan says; I'm not young enough to know everything.
😅
Thanks to Ankan, Saurabh, and Maja for helpful feedback on this long post.
- tobben